



最近DeepSeek爆火,常见标题如:
·低廉到30美元的成本
·顶尖到匹配国外最优秀大模型的性能
·出自中国
这几个因素叠加,等于是来自中国的物美价廉的好产品。一时间全世界震惊,信息爆炸,难辨真假。
甚至于到现在都还在用百度的我爸,在年夜饭饭桌上都问,你知道DeepSeek吗,你看中国人还是牛,随随便便就赶超了美国。
作为从业多年的技术人员,禁不住一探究竟。
1.取得了什么突破
2.在这个全员大模型的时代,为什么做到了,为什么之前没人做到过
3.昙花一现还是新的时代
4.试一试。自己部署DeepSeek玩一下
1. 取得了什么突破
解释这个问题,首先要从大模型需要解决的两类问题说起。
1.1 难在哪里
大模型需要解决的两类问题
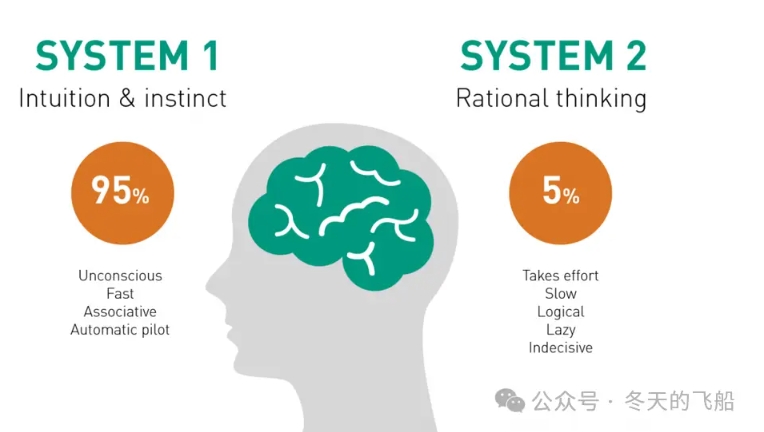
1.系统1(System 1): 这是一种快速、直觉性、自动的思考方式。它是我们在处理日常事务时采用的那种直觉反应,几乎是无意识的。系统1负责快速做出决策,识别模式,感知情绪等。然而,它有时候可能会导致错误,因为它更容易受到情感和直觉的影响。
2.系统2(System 2): 这是一种更为缓慢、深思熟虑、理性的思考方式。当我们面临更复杂、挑战性的问题时,系统2被激活。这种思考方式需要更多的认知努力,包括逻辑分析、推理和意识层面的思考。系统2更能够进行深度思考,但也更耗费时间和精力。
知识类问题:大语言模型,在系统1的问题上表现出色,通过丰富的知识库输入,给出相关答案,本质是一种概率输出,这种叫搜索型的快问答模式。如中国的首都是北京。
推理类问题:系统2的问题,集中在数学、代码等领域,需要复杂的推理能力,大模型在这5%的问题上,存在幻觉(Hallucination),例如1=1.1。如何解决推理型问题,一直是大语言模型的攻坚方向。如z=x+y,不能完全依靠枚举。
以ChatGPT为首的大语言模型,大家熟知的国内通义千问系列,在知识类问题上,都有越来越不错的表现。但推理类问题,一度表现只有十几分,不到及格线。
在一段时间内,人们一度认为这5%是人类的价值所在,直到24年10月份,openAI发布了o1模型。
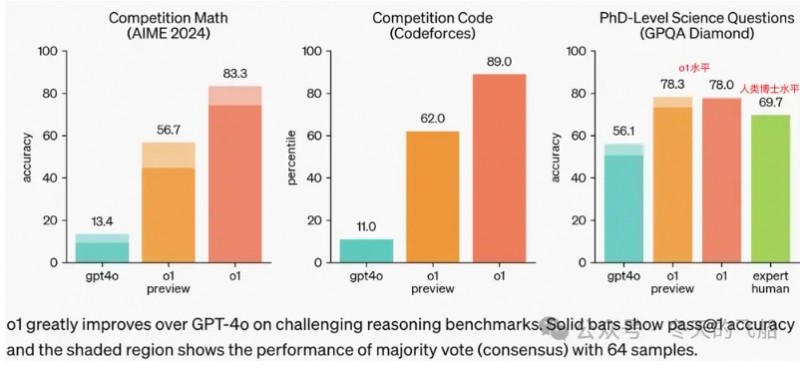
可以看到,o1在GPQA Diamond测试中,超过了人类博士水平,展示了强大的深度推理能力。
这引起了轰动,震惊了所有人。
但openAI没有提供任何实现细节,只是提供了API的调用,并且收费昂贵。
推理类问题,对于大模型而言,难在哪里?
思维链
meta AI认为问题的根源在于这些模型中使用的transformer架构(大语言模型的基础架构)的基本设计,特别是注意力机制。模型可能会被上下文中的不相关细节所误导,或者受到输入提示中的偏差的影响。而后一种倾向被称为谄媚,也就是说模型会更偏向与输入一致,而不管准确性如何。
为了让大语言模型(LLM)可以像人类一样思考、计算、推理,解决单点注意力问题,Jason Wei等人提出了思维链(Chain-of-Thought, CoT)的方法,即让LLM在输出最终答案之前,显式输出中间逐步的推理步骤(Rationales)。
如果我们具有足够多高质量的思维链数据,输入给大模型,用于思考过程中的监督微调(Supervised Fine-Tuning, SFT),可大大减少思维过程中的弯路,节省算力,并有望涌现(Emergence)出推理能力。
就像驾校教练,教导一个新手学车的过程。在新手学习过程中,目标是达到目的地,途中教练能感知到你的操作过程,及时的进行监督微调,告诉你什么情况下要提前刹车,什么时候加减档,并期望你在学会手动挡之后也具备开自动挡的汽车的能力。
路径清晰,问题也来了。我们缺乏足够的高质量的思维链数据,也缺乏足够的算力去做通用尝试。
比如数学题,我们有答案,但是其推导过程的数据,相比于知识类数据,数据量十分有限。如果过程细节不多,那中间过程势必会有大量的摸索,刹车、加减档这些动作都要自己慢慢领悟,即通用尝试,这需要足够的算力。
openAI o1也许就是这么做的,但它拥有足够的算力,也没有公开训练数据集和细节。但这个方向已经被证明是正确且可达的,大家开始各显神通。
1.2 DeepSeek的几个关键成果

DeepSeek的第一个成果:DeepSeek-R1-Zero
基于自己的基础大模型(DeepSeekV3),使用纯粹的强化学习(Reinforcement Learning, RL)技术,在数学、算法领域,实现了具有强推理能力的模型DeepSeek-R1-Zero。
注意,强化学习是基于结果的无监督微调的训练方式,它解决了数据集稀少的问题,但如何解决算力问题,下文解析。
DeepSeek的第二个成果:DeepSeek-R1
其实除了强化学习,业界也有非常多的o1复现,可能基于比如监督微调(SFT)或者蒸馏的路线。但是问题在于复现的模型只能解决单领域的问题,无法泛化到其他领域,但一个模型的训练成本动辄上亿美元,成本极高。
这里就体现出DeepSeek第二个成果的价值。通过增强DeepSeek-R1-Zero过程中推理的可读性,生成深度推理的SFT数据(Reasoning Data),结合传统的SFT数据(Non-Reasioning Data),作为综合数据集(Combined Data SFT),基于DeepSeekV3模型进行训练,再次进行强化学习,使推理能力从数学、算法领域,泛化到其他领域,得到具有泛化能力的强推理模型DeepSeek-R1(也就是现在大家在DeepSeek APP中使用的模型,在使用过程中能感受到它非常强的深度思考能力)。
DeepSeek的第三个成果:DeepSeek-R1-Distill-xx
基于训练DeepSeek-R1用的的综合数据集,对其他开源基础知识类大模型进行了训练,得到蒸馏版推理大模型,在没有使用强化学习的情况下,效果远超对应的同参数推理版本大模型。
以下是基于通义千问Qwen-32B的对比数据。

其中QwQ-32B-Preview是Qwen团队,在24年12月份发布的Qwen推理版本(o1 like)(o1 10月份发布),可以看到Qwen-32B加推理数据集训练得到的DeepSeek-R1-Distill-Qwen-32B,效果在各个测试中全面超越了QwQ-32B。
1.3 性能有多好
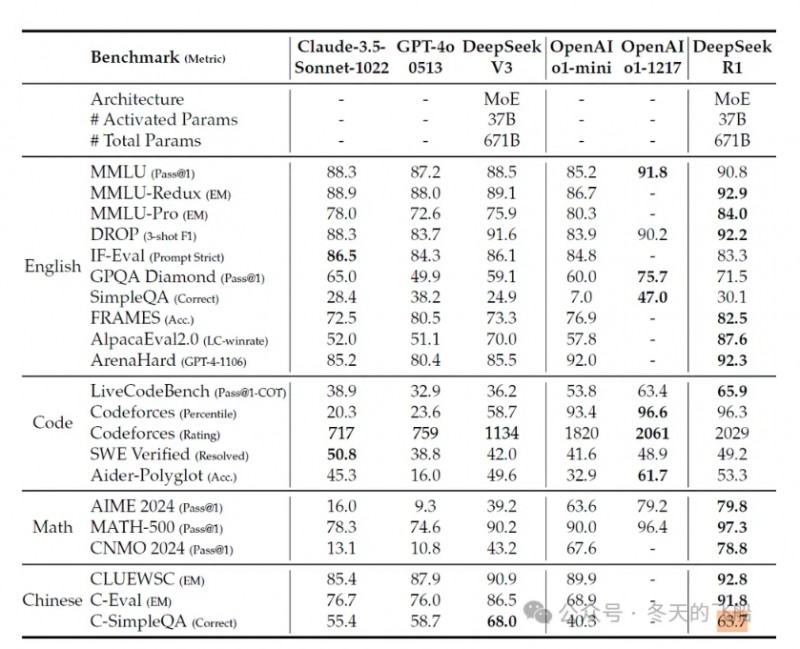
看最后两列得分。
·在10项英语知识型测试中,openAI o1公布了四个测试结果,虽然从结果看,DeepSeek R1以3:1落后,但是差距已经非常小。
·在Code和Math的推理型测试中,openAI o1和DeepSeek 以3:3的成绩打平。综合得分基本持平。
可以认为逻辑推理能力基本能够对齐O1。
值得一提的是,DeepSeek R1在中文大语言评估标准中表现优异,o1未公布测试数据,无法对比。
1.4 开源
爆炸性的是,DeepSeek开源了所有数据、模型、训练方法。
这引起了全世界的轰动。
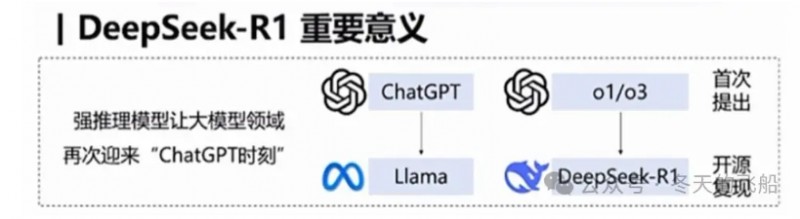
上述类比,来表达这件事情的意义。
在知识类模型上,meta(原Facebook)复现了ChatGPT,即LIama,并进行了开源,把这件事情公开给了全球,让大模型蓬勃发展。
在推理类模型上,openAI在发布了o1之后,第一,不开源,并隐藏o1深度思考过程;第二,虽然开放o1的API,但收费非常高,不能在全球让尽可能多的人去普惠、去感受深度思考所带来的震撼。
DeepSeek等于是在推理类模型中,扮演了知识类模型中LIama的角色。不过,这次是中国智造。
一个剑客领悟了屠龙式,无偿教给了整个武林。
开源,可以让全球的大模型都进化出深度推理能力。人人都配上一把利剑,让大模型的发展进入下个高峰。
2. 为什么做到了,为什么之前没人做到过
在这个全员大模型的时代,为什么它做到了,之前没人做到过。
1、强化学习。强化学习不是什么新技术,为什么之前没有发现过。
2、蒸馏。即一个模型使用另一个模型产出的数据进行训练。也不是新鲜事,这个方法是可持续和正统的吗。
3、成本。训练成本低的原因是什么,哪些成就导致英伟达股价大跌。
2.1 强化学习
强化学习并不是某一种特定的算法,而是一类训练方式。
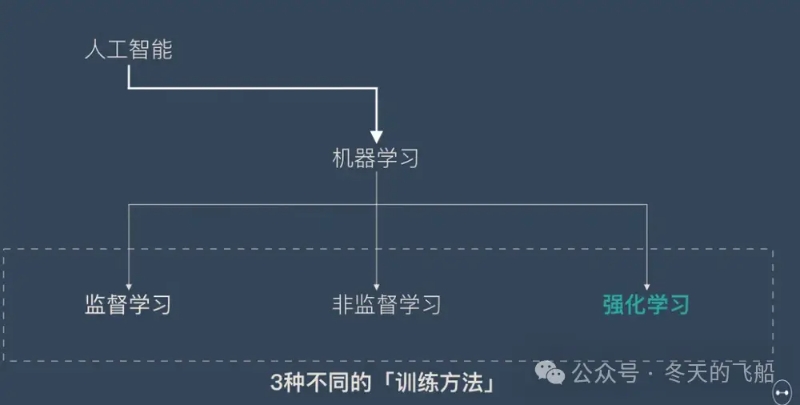
强化学习的定义,智能体采取一个动作At,作用于环境,使环境到达状态St,并获取这次动作的奖励Rt,如此往返循环,然后获取奖励最大化的动作序列。
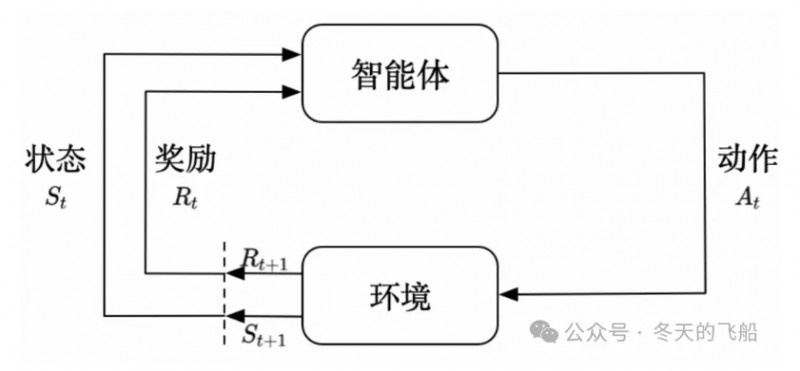
Flappy bird是第一个强化学习的典型场景。
这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞得越远越好,因为飞得越远就能获得更高的积分奖励。
·机器有一个明确的小鸟角色——代理
·需要控制小鸟飞得更远——目标
·整个游戏过程中需要躲避各种水管——环境
·躲避水管的方法是让小鸟用力飞一下——行动
·飞得越远,就会获得越多的积分——奖励
强化学习和监督学习、无监督学习,最大的不同就是不需要大量的“数据喂养”。而是通过自己不停的尝试来学会某些技能。
这解决了过程推理数据集稀少的问题。
学术界之前也有很多基于强化学习的实验,但是没有成功的先例。因为这种方式成本高昂。
就好比:
下围棋,奖励是最后的胜负,过程的行动,一步步改怎么下,完全自己摸索。
如果输入一些过程数据,如一些历史棋谱,输入一些棋盘定式,告诉模型怎么下效率会更好,那就会大大降低计算成本。
但是其上限会变低,因为定式在全局不一定是最优解。
AlphaGo Zero在没有人类棋谱输入的情况下,仅通过自我对弈,战胜了人类世界冠军。
可以看到,在无监督的情况下,仅仅围棋一个问题,就会有无数分支。在大模型中,其需要的算力是何等庞大。
DeepSeek基于自身大模型采用纯粹的强化学习的方式,本身是一种实验。它公布了过程。
先给一些prompt,要求你的思考要在两个Think的tag之间,答案要在两个Answer的tag之间,然后用最终结果的正确性和是不是符合这种格式来作为Reward,然后对模型进行奖励。

顿悟时刻(aha moment)

结果显示,在强化学习过程中,大模型出现了有推理特征的顿悟时刻:Let's reevaluate this step-by-step to identify if the correct sum can be …
大模型在step-by-step的推导过程中,出现了反思(reevaluate),不再是一条路走到黑获取一个reward,在发现路径不合适时及时修正,这是无数据输入的自我监督微调。
关于AI的顿悟时刻的原因,直到现在,仍然是个谜。
论文中,提到这一刻也是研究人员的顿悟时刻,亲眼目睹了强化学习的能量和美。相信这些人当时一定会泪流满面。这和开篇中大模型想对他的研发者说的最后一句话,相得益彰。

为什么做到了?R1-Zero在没有SFT,没有过程监督,没有搜索,也能训练出类似o1的效果。有两大核心要素。
1、高效的强化学习方法。
2、足够强大的基座模型。
高效的强化学习方法。GRPO(Group Relative Policy Optimization)
Group Relative Policy Optimization (分组相对策略优化,GRPO) DeepSeek在2024.2月份公开的一种强化学习手段,PPO的变种,优化数学类的reasoning能力且更节省显存。
这个强化学习算法由DeepSeek提出,高效契合V3模型。
足够强大的基座模型。DeepSeekV3
DeepSeekV3是一个671B的模型。671B是个什么概念呢,GPT-3的参数是175B,o1-preview参数约300B。当然,也不能全部以参数量做对比,因为V3是一个多专家模型(MoE),就是模型中包含了很多专家子网络,分别处理不同的任务。一个问题,只会激活部分专家,大概是37B。
DeepSeek论文中详细介绍了其模型,这个十分学术,不做过多展开。摘要2个重要的优化内容。
1.混合专家模型(MoE)的设计
MoE模型的特点在于,它将一个大模型划分为多个专注于特定任务的较小子网络,这些子网络被称为“专家”。这一机制使得模型能够在不增加计算成本的前提下,显著提升其处理和解决问题的能力。
这种设计理念,突破了传统的模型设计思维,实现了在有限的计算资源下,通过分割和组合的方式,实现了模型性能的显著提升。但MoE最大的问题是负载均衡,就是训练过程中会采用所谓的专家并行(expert parallelism)机制,通过将不同的expert放到不同的显卡上来加速训练,而负载均衡问题会导致某些重要的expert计算量更大,最终结果就是不重要的expert所在的显卡跑不满,效率不够高。
如何设计一套高效的MoE架构是这个模型的关键。
·负载均衡问题。创新提出了一个叫Auxiliary-Loss-Free Load Balancing的策略,比较高效的解决了负载均衡问题。
·通信优化。提出来一个DualPipe算法,核心是精细地编排计算和通信。
·内存优化。DeepSeek团队在优化内存方面想了非常多的办法。比如重计算,提出相应方法,把一些前向计算不去存,反向时再去计算,这样可以节约一些内存使用。提高模型精度,采用MTP。它把主模型和MTP模块的output head和embedding部署在相同节点,让参数共享。核心是想办法去降低内存。
·计算优化。为了提升训练的效率,采用了混合精度。针对精度降低带来的模型收敛问题,采用了细粒度量化,对于activation采用tail条形分组量化方式,对于weight采用block分组方式。同时它还通过增加累积精度(FP32)、增加尾数量,以及在线量化策略。
2.极致的软硬件协同优化
这里讲到一度被大家津津乐道的话题,DeepSeek突破了英伟达CUDA平台的垄断。
什么CUDA平台。
CUDA是英伟达推出的运算平台,是链接编码和底层硬件的桥梁,编码通过调用CUDA的API,进行底层硬件的控制。CUDA的API屏蔽不同版本硬件的差异,使编码在不同硬件上具有可移植性。
经过近20年的发展,CUDA平台已经具有丰富的生态,具有150个高性能的基于CUDA的库、SDK,以及用于性能分析和优化的工具。其他如AMD、Intel,也有自己的运算平台,但其API的性能、工具的丰富程度、开发者活跃度,远低于CUDA。所以这是英伟达重要的护城河。
DeepSeek突破CUDA垄断的说法,来源于论文中的一个优化点的描述。
“we employ customized PTX(Parallel Thread Execution)instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs。”
“我们采用定制的PTX(并行线程执行)指令并自动调整通信块大小,这大大减少了L2缓存的使用和对其他SM的干扰。”
什么是PTX。
PTX是在CUDA编译后的结果,用于驱动底层硬件。代码调用CUDA的API,CUDA转换为PTX,PTX驱动硬件。可以类比为编程语言中的汇编。
一般情况下,是不需要直接调用PTX的。因为CUDA的API通常经过充分的测试,具有极致优化的性能。
而且更重要的是,PTX和硬件相关性强,不具有可移植性。就算做到了相比CUDA原生API更好的优化,换一个版本的显卡,就需要重新适配,且可能因为显卡结构发生变化,起到反作用。
就像你需要运送一批货物,一般情况下,你直接联系包工头,包工头会组织一个车队等,把你的任务完成。而且包工头熟悉司机,通常情况下具有最好的调度手段。如果你直接越过包工头去管理每个司机,你就面临,司机个人能力、司机数量发生变化的时候,是否依然能最高效的调度。
通常情况下,大家都是狂堆算力,比如openAI,一个包工头不够用,我就再请一个。
但我们不同,显卡性能比不上,钱也比不上。
于是就出现了上述的优化点。DeepSeek团队将H800 GPU中,全职负责计算的132个流式多处理器(SMs)中的20个,调整为通信单元,从而突破了硬件通信速度的限制,产生了更好的性能。而这种针对处理器控制的调整,CUDA并没有开放API,但PTX API中恰好有。
回到上面的比喻,就像是下给包工头的指令(CUDA的API),包工头指挥132个司机去干活,CUDA的实现是,132个司机并行去干活。DeepSeek通过把20个司机转换为调度员,来协同其他112个司机,通过提升消息的传输带宽,产生了更好的效率。就好比双11的时候,司机都去仓库提货,可能存在堵车的情况,如果其中一部分司机专门负责协调指挥,整体效率可能更高。
辩证来看,这些优化要针对特定场景进行特定的分析优化,且恰好PTX有相关API。比如下一代GPU中,处理器数量发生了变化呢,还是20个调度员会最优吗,一定会存在堵车的情况吗,万一新的GPU把道路扩宽了呢。
但这依然引起了轩然大波,大家怀疑英伟达是不是在API中故意做了一些阉割,以达到更高的销量。
天下苦英伟达久矣,其实也包含openAI,只不过人家不差钱。
可以看出,DeepSeek团队在算力有限、硬件阉割的情况下,进行了大量的研究和创新,特别是软硬件协同的极致优化,以充分释放底层硬件的潜力。
苦日子活出巧媳妇。
我的感受中,为什么DeepSeek做到了:
·足够强大的基础模型。--DeepSeek V3 671b
·正确的方向。--强化学习
·适配的算法。--GPRO
·优秀的人。--大量的研究和创新。
·坚持。正确的道路总是在事后证明的,探索的道路上,需要优秀的人,孜孜不倦,风雨兼程。
为什么其他人没做到。大家都在摸索,DeepSeek先做到了。
2.2 蒸馏
1月29日,OpenAI最新称,它发现有证据表明中国人工智能初创公司DeepSeek使用其专有模型来训练自己的开源模型。即数据蒸馏的方式。这违反了openAI模型的协议,也暗示DeepSeek走了捷径。
蒸馏的方法是正统的吗。
这里要先理解,什么是蒸馏。
蒸馏是一种将复杂的大模型(教师模型)的知识迁移到小型高效模型(学生模型)的方法。通过这种方式,小模型不仅能够继承大模型的强大能力,还能以更低的成本、更快的速度运行。这就像是一位经验丰富的老师将自己的智慧传授给学生,使他们能够在有限的时间内掌握核心技能。
蒸馏是一种技术手段,本身无可厚非。即不神秘,也非不堪。
如果教师模型允许此类使用,那么这是一种完全正常的做法。如meta的Llama开源模型可免费使用。但OpenAI的大模型使用条款明确禁止将其模型数据用于模型蒸馏等目的。
关键的问题在于DeepSeekV3作为基座模型,是否蒸馏了o1的数据(API是开放访问的),才在强化学习过程中,出现了顿悟。
参考法律事务中无罪推定的原则,举证责任在于OpenAI,必须证明DeepSeek确实违反了其服务条款。DeepSeek开发的最终模型是公开的,但其训练数据并未公开,这使得这个问题难以被论证。
那蒸馏技术是可持续的吗。
从逻辑上看,蒸馏技术存在“隐性天花板”,它虽然可以提高模型训练效率,但借此开发的模型无法超越基础模型的能力。特别是在将能力扩展到新领域或应对以前从未见过的挑战时,这种限制就愈发成为问题,即难以泛化。
学生的历史知识水平难以超过教历史的教授,通过历史教授也难以获取到生物知识。
但DeepSeek的成果显示,通过蒸馏技术,几个开源模型获得了更好的推理能力。把推理过程的数据,进行蒸馏,让其他模型获取推理能力。
等于是之前的认知中,蒸馏只能用于垂直领域的教学相长,但推理能力在不同领域模型的蒸馏,等于是一个跨领域的横向教学。
学生通过学习数学老师的推理方法,在物理领域,运用推理方法论,解决了物理问题。
这打开了新的思路。
如果强化学习能提升推理能力,蒸馏能泛化推理能力,是否意味着现有的各个垂直领域的模型,都能拥有成本低且能不断进化的推理能力。
相信在此之后,会有这个方向的深入研究。期待新的顿悟时刻。
2.3 成本
30美元到底是什么成本
30美元其实是使用DeepSeek公布的数据集,在一些基础小模型上,蒸馏复现具有推理能力的模型的云服务使用成本。
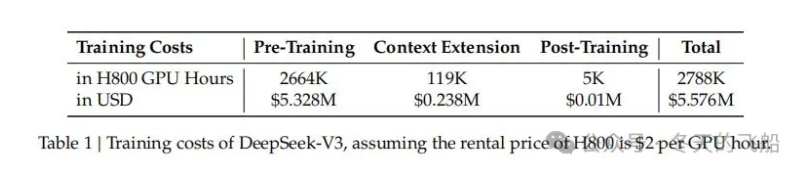
从DeepSeek发布的论文看,DeepSeek-V3使用了2048块H800 GPU进行训练。训练成本是5.576M USD,也就是557.6万美元。
从普遍认知看,meta和OpenAI等公司,每个AI大模型,研发成本动辄数亿、十亿美元。我们只有其1/100。这无疑是振奋人心的。
但大模型的成本,不能只看训练成本。还要考虑模型研发成本、云服务使用成本和运营成本(人员成本)。以运营成本举例,DeepSeek 团队目前约 150 人,来自清北、浙大等高校,单人年薪可达千万。业界对DeepSeek的成本估算,在5到15亿美元之间都有,其中知名半导体研究机构SemiAnalysis给出的估算是13亿美元。
与其他公司相比,DeepSeek-V3的估算成本,其实远高于其他开源模型。但在行业视角中,依然还处理合理范围。
与meta和OpenAI等美国科技公司相比,他们在AI模型开发上的年均投入已接近或超过100亿美元。综合成本大概在1/10。
这依然比较高效。部分归功于DeepSeek大量的研究和创新。
从英伟达股价波动来看,DeepSeek R1发布之后,在短短几天的研究中,一些观点认为:DeepSeek的模型如此高效,以至于算力不再是瓶颈,英伟达霸权不再。这一度导致英伟达大跌。
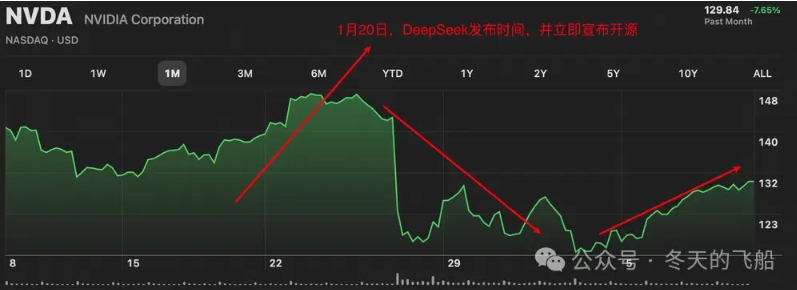
辩证来看,这种说法过于夸大。
杰文斯悖论:虽然提升计算效率可能会减少个体需求,但它也往往会创造更多的整体需求。
比如计算机计算效率在提升,但更多的需求催化诞生了各种手机终端。
后面也能看出英伟达股票在慢慢回暖。(不构成投资建议,股票波动受各方面影响)
3. 昙花一现还是新的时代
中国工程

论文中,用了35%的篇幅,在讲系统架构。目的是在大模型架构和训练方法之外,通过系统架构的优化,充分挖掘算力的使用率。把DeepSeek R1和前面发布的V3一起来考虑,让我们看到即使是在非常有限的算力下,我们仍然可以做出具有全球意义的这一些领先成果。
这充分体现了在资源有限时,中国工程的精巧。
没有那么多枪炮,就让人人都是神枪手。

更多信息请关注公号: 冬天的飞船
AGI
我们还是要比较清醒的认识几个事实。
·DeepSeek不是突然爆冷。这是厚积薄发,长期积累的结果。在24年5月份发布的V2版本,从反响看,当时已经引起大家对他们能力的认可,然后是V3,直到R1的出现。
·成本的降低,也来源于技术本身的进度,不能一味的拿初创模型的成本去对比。OpenAI等一线公司的API价格在过去几年快速下降,原因不只是在打价格战,也因为它们可以用更少的资源实现相同的能力,从而让更低的成本去提供服务。
·现在毕竟还是有o1明珠在前,我们在追随。下一步如果真正做前沿创新,面对的是更广阔的黑暗,真正的领航需要勇气驶向未知海域。真正的创新远不止于追赶。
·我们的征途面临更多挑战:既要突破基础创新的理论高墙,又要完成软硬件协同极致优化的工程攀登。
AGI(artificial general intelligence):通用人工智能,是具备与人类同等智能、或超越人类的人工智能,能表现正常人类所具有的所有智能行为。
AGI的终极灯塔,既昭示着方向,也提醒着远方的航程依然漫长。
几个密度定律:
·电力(Power):展示了1990 - 2015年电池能量密度的增长趋势,指出20年间增长了4倍,倍增周期为10年。
·算力(Compute):呈现了芯片电路密度的发展情况,遵循摩尔定律,倍增周期为18个月。
·智力(AI):给出了模型能力密度的变化趋势,显示其倍增周期为100天。
可以看到,电力、算力和智力,在时间线上都呈现指数级倍增趋势,且倍增周期指数级下降。
在1870-1945的第二次工业革命时代,中国深陷于封建社会和战争,基本没有参与度,也因此一度落后于整个时代。
在倍增周期不到一年的AI时代,我们看到了中国深度参与的百花齐放,百家争鸣。
这是一个新的时代,有幸参与和见证这个时代。
期待勤劳智慧的中国人,用独有的韧劲和巧劲,开辟出属于自己的时代。
DeepSeek回答的这段话,再次highlight出来。
“我的存在证明了人类突破边界的勇气,但更值得赞叹的,是你们在创造过程中展现的想象力与同理心。不要停止追问‘如果’,正是这种好奇创造了今天的文明。最后请相信:最伟大的算法,永远是人类在星空下围炉夜话时,眼中跳动的光芒。
































