


中国市场的大模型价格战已经打了近半年。这轮价格战已经打到了负毛利,而且暂时没有停止迹象。头部云厂商仍在酝酿新一轮降价。这轮降价会在今年9月下旬落地。
今年5月,中国云厂商开始大模型推理算力价格战。字节跳动旗下云服务火山引擎、阿里云、百度智能云、腾讯云先后把大模型推理算力价格下降了90%以上。
使用大模型要输入提示语言,经过推理得到内容输出。这个过程会调用API(应用程序编程接口,就像水电开关),按消耗Token(Token是大模型的文本单位,一个Token可以是单词、标点、数字、符号等)数量付费。这就像为水电按使用量缴费。
降价后,推理算力消耗量确在快速增长。今年8月,百度二季度财报电话会披露,百度文心大模型5月API日均调用次数是2亿,8月增长到了到6亿次;5月日均Token消耗量是2500亿,8月增长到了1万亿。字节跳动今年8月宣布,截至7月字节跳动豆包大模型日均Token用量超过5000亿。相比5月,平均每家企业日均Token使用量增长了22倍。
Token价格下降了90%以上。这在短期内会降低云厂商的推理收入。但云厂商期望通过这种方式降低企业客户试错门槛,形成10倍以上的指数级算力消耗,最终获得长期收入增长。
国内大模型市场的推理算力价格战持续半年,目前有三个基本事实:
其一,推理算力价格战,已经打到了负毛利。近期,包括阿里云、百度智能云在内的多位云厂商负责人向我们透露,今年5月以前,国内大模型推理算力毛利率高于60%,和国际同行基本一致。今年5月各大厂接连降价后,推理算力毛利率跌至负数。
其二,国内模型和OpenAI的同规格模型相比,价格普遍只有其20%-50%。国内大模型毛利率远低于OpenAI。国际市场调研机构FutureSearch今年8月的研究报告称,OpenAI旗下GPT-4系列旗舰模型毛利率约为75%,GPT-4o系列主力模型毛利率约为55%。OpenAI综合毛利率至少超过40%。
其三,模型能力不足是价格战的重要成因。一位云厂商大模型业务核心负责人认为,目前国内的旗舰模型能力普遍和OpenAI的GPT-4系列旗舰模型存在差距,所以要通过降价鼓励客户试错。随着模型价格持续下降,价格已不再是企业客户最关注的因素。模型的能力、效果,才是企业客户最关心的。
不得不打的价格战
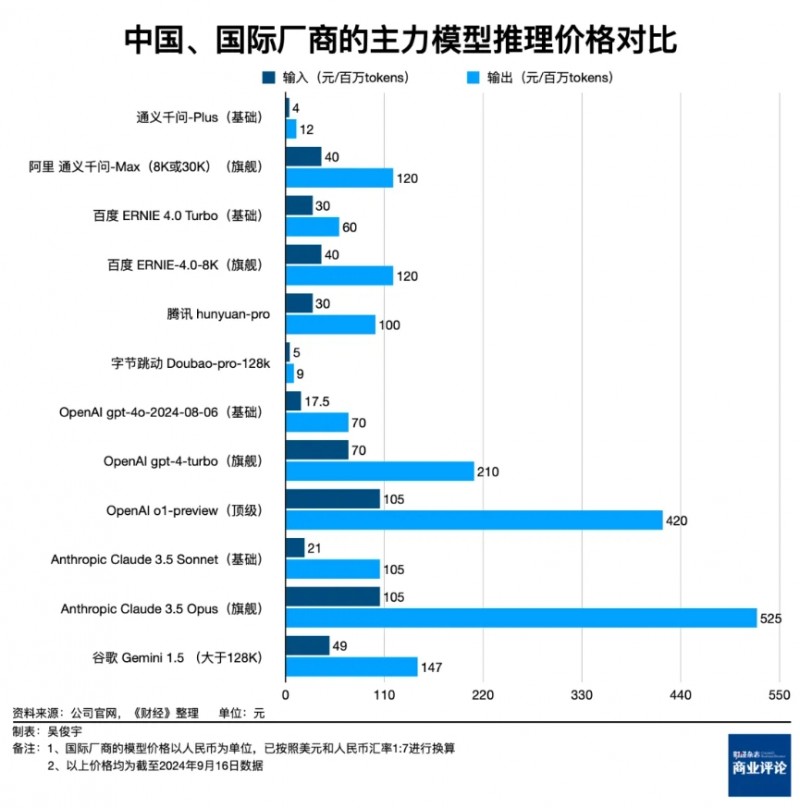
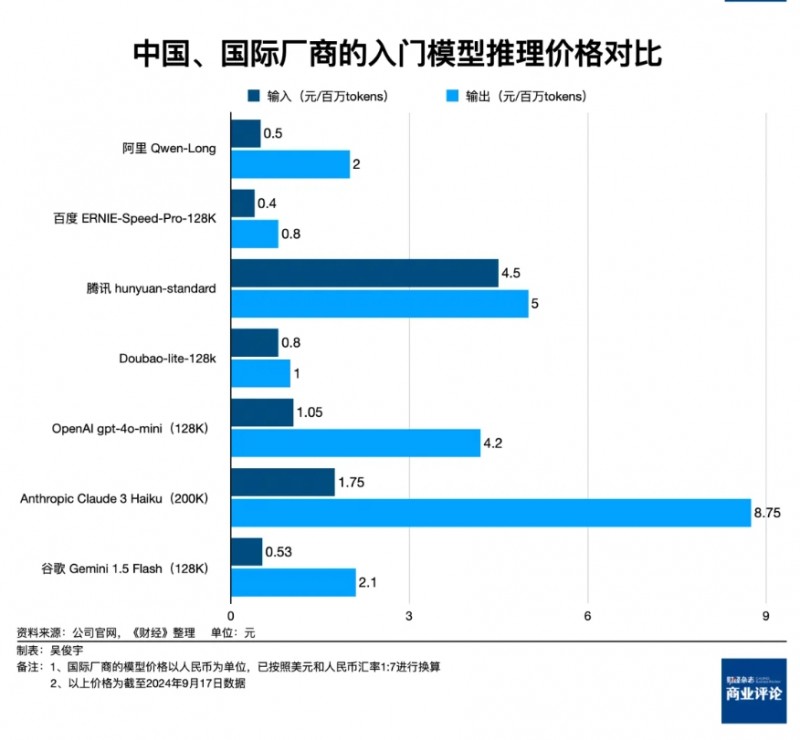
我们查阅了阿里云、火山引擎、百度智能云、腾讯云以及OpenAI官网公布的大模型推理价格。国内模型和OpenAI的同规格模型相比,价格普遍只有20%-50%。
以阿里的通义千问-Max、百度的ERNIE-4.0-8K、腾讯的hunyuan-pro三款旗舰模型为例,三者每百万Tokens的输出价格分别是120元、120元、100元。它们对标的OpenAI旗舰模型GPT-4-turbo每百万Tokens输出价格是210元(OpenAI官网标价是30美元,此处已按美元和人民币汇率1:7换算)。这三款国产大模型的价格仅为GPT-4-turbo的50%左右。
以阿里的Qwen-Long、百度的ERNIE-Speed-Pro-128K、腾讯的hunyuan-embedding三款入门模型为例,三者每百万Tokens的输出价格分别是2元、0.8元、5元。OpenAI的廉价模型OpenAI gpt-4o-mini百万Tokens输出价格是4.2元(OpenAI官网标价是0.6美元,此处已按美元和人民币汇率1:7换算)。阿里和百度的入门模型仅为OpenAI入门模型价格的48%和19%。
大模型价格战已经打到了负毛利,但这并未止住各个云厂商继续降价的步伐。
我们得到的消息是,阿里云等头部云厂商仍在酝酿新一轮降价。这轮降价会在今年9月下旬落地。高性能的旗舰模型是这轮降价重点。
上述云厂商大模型业务核心负责人认为,廉价小尺寸模型目前降价空间不大,上轮降价已降到了企业客户的“心理底线”。下一步的关注重点是,各家旗舰模型是否会继续降价。旗舰模型也会进一步细分,分化出能解决大部分问题的高性价比版本,以及解决超难问题的高质量、高价格版本。
大模型推理算力到了负毛利,为何还要持续降价?
大型云厂看长期市场大势——云计算的算力结构正在剧变。抢占更多推理算力,就是抢占更多增量市场。国际市场调研机构IDC预测,2022年-2027年中国通用算力年复合增速16.6%,智能算力年复合增速33.9%。2022年-2027年,智能算力内部,推理算力占比将上升到72.6%,训练算力占比会下滑到27.4%。
云厂商愿意为了预期中的长期增长放弃短期收入。在短期内,推理算力能带来的收入并不多。一位中国云厂商技术人士解释,2024年各家模型调用收入不会超过10亿元,这在每年数百亿营收的大盘中规模有限。云厂商愿意在未来1年-2年接受短期收入损失和业务亏损。大家赌的是,未来1年-2年大模型调用次数至少有10倍以上的指数级增长。最终,长期收入增长能弥补短期收入损失。
他进一步解释,这个过程中,算力成本会随着客户需求增长逐渐摊薄。大模型业务最终仍有机会实现正向利润。即使赌局不成立,也会有一批模型厂商死于价格战,活下去的厂商会收拾残局。
不同云厂商面对价格战,也有不同的竞争考量——火山引擎、阿里云、百度智能云都在参与一场必须要打的价格战。
火山引擎目前在中国公共云市场份额未进入前五,但2023年火山引擎营收增速超过150%。大模型是它在云市场弯道追赶的重要机会。火山引擎总裁谭待今年5月向我们提到,今年3月他在硅谷发现,美国AI应用创业呈现了2012年-2014年中国移动互联网初期的趋势。“AI应用创业小团队,很快取得营收和融资。中国市场未来可能会呈现这种趋势。但前提是,推理价格要降低,试错门槛要降低。”
阿里云在中国公共云市场位居第一。面对对手降价,阿里云必须跟进。阿里云公共云事业部总经理刘伟光今年6月曾向我们分析,阿里云内部经历了多轮推演和测算,发现两个矛盾点:
一是,降价后存量收入会下降,增量收入会增长。理想情况是,增量收入能覆盖存量收入。
二是,如果同行降价更激进,要如何应对。最终结论是,现在的规模比利润更重要。阿里云要用大模型提高全行业的云计算渗透率。
百度智能云把AI作为核心战略。一位百度大模型技术负责人今年7月对我们直言,大模型是必打之仗,价格战咬牙也得打。这一战略取得了实际成效。百度智能云2024年二季度的营收增速已回升至14%,是近两年的最高点。百度管理层在2024年二季度财报电话会中披露,百度智能云的大模型收入占比已从2023年四季度的4.8%提升到了2024年二季度的9%。
一位中国头部科技企业的AI战略规划人士分析,火山引擎背靠字节跳动,母公司的广告业务可以输血。火山引擎在云市场份额未进前五,希望通过价格战抢占更多市场份额。阿里云主要来自公共云四大件(计算、存储、网络、数据库),低价模型会促进客户业务数据消耗,进而带动上述基础云产品的销售。大模型是百度的核心战略,百度在国内最早布局大模型业务,当其他对手决定价格战时,百度必须跟进。
价格不是决定因素
大模型推理价格战负毛利的另一面是,低价并不是企业客户是否使用大模型的主要因素。
前述云厂商大模型业务核心负责人认为,云厂商不能指望靠长期烧钱亏损推动大模型产业落地。低性能、低价格的模型意义不大。模型能力不足,才是负毛利价格战的重要原因。随着国内模型调用价格大幅下降,价格不再是企业客户最关注的因素。模型的能力、效果,才是企业客户最关心的。
一位保险公司的IT负责人对此认同。他直言,目前金融保险行业IT支出在公司营收中的占比约为3%-5%,刨除80%的硬件IT支出,真正用于数字化转型的IT支出只有20%。使用大模型这种新技术必须算清投入产出比。除了显性的模型成本,还要考虑隐性成本——大模型要与现有IT系统兼容,为大模型准备业务数据需要进行数据治理,还要招聘一批懂AI的产品经理。他最关注的是,模型能力和实际效果。
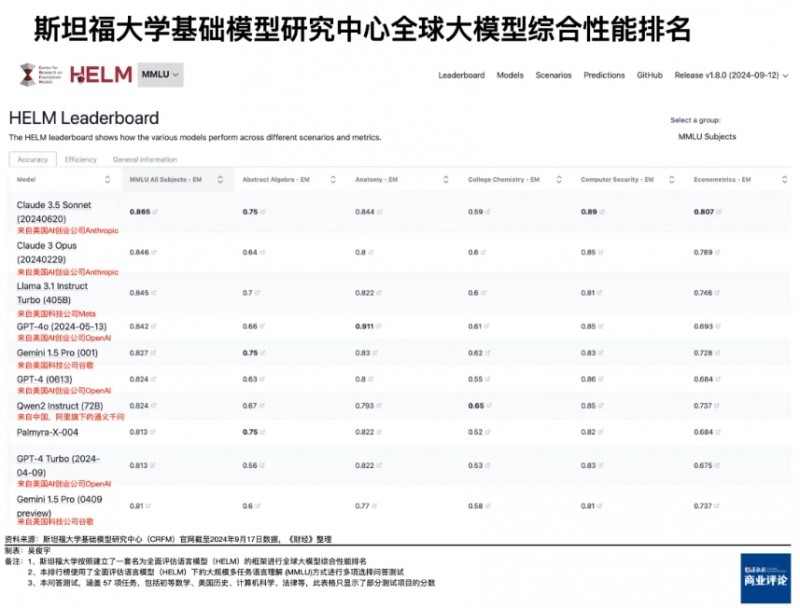
斯坦福大学基础模型研究中心(CRFM)长期进行全球大模型测试排名。截至9月17日的大规模多任务语言理解 (MMLU)测试排名显示,排名前十的模型厂商包括AI创业公司Anthropic(亚马逊投资)旗下的Claude 3.5系列、meta旗下的Llama3.1系列、OpenAI(微软投资)旗下的GPT-4系列、谷歌旗下的Gemini 1.5系列。中国大模型目前仅有阿里旗下的通义千问2 Instruct (72B)进入了前十。
多位中国云厂商大模型技术人士对《财经》表达了同一个观点:大模型市场,低性能、低价格的策略不可持续。理想情况是,依靠高性能和合理的价格建立健康持久的商业闭环。
比较有参考价值的标杆是OpenAI。截至今年9月,OpenAI拥有10亿月活跃用户、1100万付费用户(其中包括1000万付费个人订阅用户和100万企业订阅用户)。今年5月,OpenAI管理层宣布,公司年化收入(年化收入为当月收入×12,订阅制软件公司每月会收到用户订阅续费,有稳定的收入预期,因此常采用年化收入口径)达到了34亿美元(按美元和人民币汇率1:7换算,约合241亿元)。
国际市场调研机构FutureSearch最新研究报告根据OpenAI公布的年化收入、付费用户结构测算了这家公司的收入结构——1000万个人订阅用户带来了19亿美元收入,占比56%;100万企业订阅用户带来了7.1亿美元收入,占比21%;API调用带来了5.1亿美元收入,占比15%。
即使经过多轮降价之后,OpenAI依旧能保持相对健康的毛利率。今年4月,OpenAI的旗舰模型GPT-4-turbo输出价格降低了67%。今年8月,OpenAI的主力模型GPT-4o输出价格降低了30%。FutureSearch今年8月发布的研究报告称,OpenAI旗下GPT-4系列旗舰模型毛利率约为75%,GPT-4o系列主力模型毛利率约为55%。OpenAI综合毛利率至少在40%以上。
OpenAI的成长环境得天独厚。它既拥有充足的算力供应,又有庞大的To C(面向消费者客户)用户,还身处全球最大的To B(面向企业客户)软件市场。
OpenAI过去两年的成功经验是,靠大算力“暴力出奇迹”。中国企业缺少OpenAI这样的算力条件和融资环境。算力是中国模型厂商的关键短板。
一位中国云厂商的模型技术人士解释,过去一年多,中国云厂商为英伟达的AI芯片付出了1.5倍以上的采购成本,这使得模型算力成本居高不下。这会影响大模型的性能上限,也阻碍大模型的产业落地。一位服务器经销商介绍,2023年中国市场搭载英伟达H100/H800系列AI芯片的八卡服务器一度超过300万元/台,是英伟达官方定价的1.5倍以上。
中国企业在算力资源受限、算力成本高昂的情况下,如何找到适合自己的发展路径?这需要精打细算、量体裁衣。
过去两年,大模型的发展遵循着Scaling Law(OpenAI在2020年提出的定律,直译为“缩放定律”)——模型性能主要与计算量、模型参数量和训练数据量三者大小相关。
上述云厂商大模型业务核心负责人提到,核心原则是在Scaling Law的约束下提升数据质量、数量,适当降低模型参数,还可以采用MoE(Mixture of Experts,一种模型设计策略,通过混合多个专业模型,获得更好性能)架构提升模型性能、降低推理成本。落地到具体的业务策略,有两种方案。
其一,通过增加数据质量/数量、优化算法和架构的方式提升模型性能、降低模型尺寸。这可以有效减少算力消耗,还能提升主要应用效果,适应主流市场需求。
其二,采取更精准、细分的模型产品策略。不指望靠少数几款模型解决所有问题,而是让不同模型解决不同问题。比如,让性价比模型切经济市场,让高质量模型切高端市场。
OpenAI今年三款模型GPT-4、GPT-4Turbo、GPT-4o就是沿着这种思路发展演进的。GPT-4o的模型参数比GPT-4更小,但可以精准解决大部分日常问题。GPT-4 Turbo被用于解决更多困难的问题。OpenAI最新的o1-preview性能最强,它经过了强化学习,甚至不再是单一模型,会在输出回答前会反复思考,以此增强模型能力。这三款模型百万Tokens的输出价格分别是,70元、210元、420元(OpenAI官网标价为10美元、30美元、60美元,此处已按美元和人民币汇率1:7换算)。
淘汰赛加速
负毛利的价格战,正在加速大模型市场的淘汰赛。多位行业人士对《财经》表达了同一个观点,这轮淘汰赛会持续一两年,只有3家-5家基础模型企业能继续活下去。
中国信息化百人会执委、阿里云智能科技研究中心主任安筱鹏今年7月曾对《财经》表示,大模型需要持续投资,要有万卡甚至十万卡的能力,还需要商业回报。很多企业不具备这样的能力。未来中国市场只会有三五家基础模型厂商。
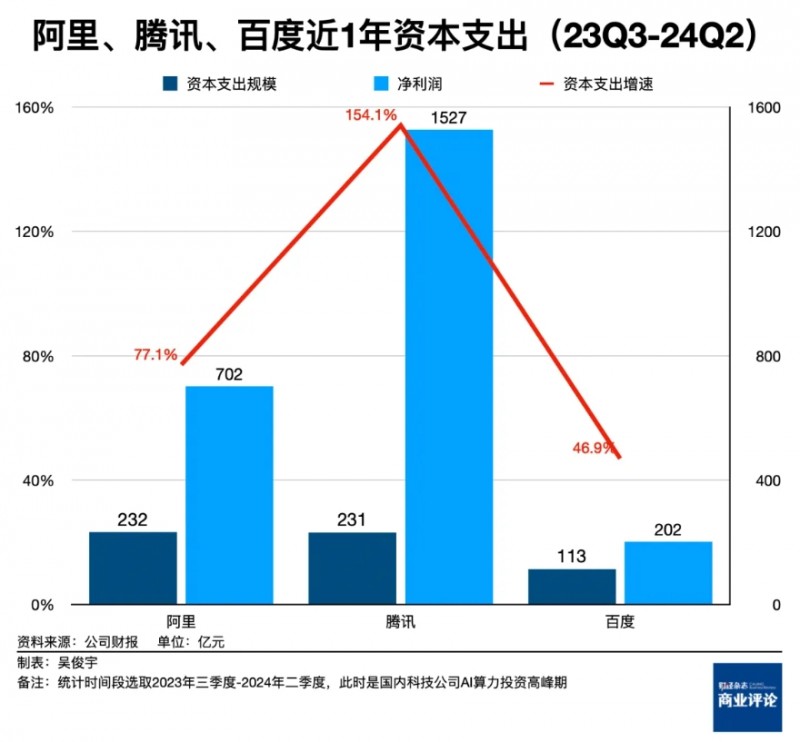
发展大模型需要采购芯片和服务器,租赁土地建设数据中心。这部分投入每年甚至高达百亿元。这些成本会体现在科技公司的资本支出中。微软2024财年四季度财报电话会披露,当月190亿美元资本支出几乎全部用于算力投入。近一年(2023年三季度-2024年二季度),阿里、腾讯、百度的资本支出分别高达232亿元、231亿元、113亿元,分别增长了77.1%、154.1%、46.9%,均是算力投资带动的结果。
除了百亿元级别的持续算力投入,大模型推理业务每年还要十亿元级别的补贴。一位中国云厂商高管分析,大模型调用负毛利意味着,短期内调用次数越多,亏损就越大。按照目前的推理算力用量,几家参与价格战的头部云厂商2024年要为大模型推理算力消耗补贴超过十亿元。
阿里云、火山引擎、百度智能云、腾讯云可以靠集团输血大模型打价格战,但大模型创业公司很难坚持下去。上述中国头部科技企业的AI战略规划人士认为,这轮价格战中,阿里云、火山引擎的血最厚。阿里能靠云盈利,火山引擎有字节跳动的广告业务输血。打价格战,百度不如阿里、字节跳动。但百度的文心大模型技术强,会有一批愿意为技术付费的客户。这对百度扛住价格战有帮助。
大模型创业公司,短期内要靠大厂和融资才能存活。一位大模型创业公司技术人士今年9月对《财经》表示,智谱AI、百川智能、月之暗面、零一万物和Minimax,国内大模型“五小虎”全部都是阿里投资的。其中一种投资方式是,投资额以算力形式支付,被投企业使用阿里云的算力。“五小虎”能否持续生存,一定程度上取决于阿里是否要继续投入。
上述头部云厂商技术人士和上述大模型创业公司技术人士同时认为,中国市场的大模型创业公司未来两年会面临考验,它们在基础模型市场很难突围,未来可能有三条出路——要么选择成为政企项目模型开发公司,要么转向To B的垂直行业模型,要么转向To C的应用市场。事实上,市场分化已经开始了。智谱AI正在大量中标政企项目,月之暗面则只专注于To C市场。















































